
- [Linux] Shell & crontab, Google Drive api를 이용한 Mysql 데이터베이스 백업 (1)
- [Linux] Shell & crontab, Google Drive api를 이용한 Mysql 데이터베이스 백업 (2)
- [Linux] Shell & crontab, Google Drive api를 이용한 Mysql 데이터베이스 백업 (3)
이번 포스팅은 시리즈 마지막 포스팅입니다.
이전 포스팅에서 Google Cloud Platform에서 프로젝트를 생성하고 Google Drive API 사용 설정과 파이썬 패키지를 설치 해 실제로 파일을 드라이브에 업로드해보는 것까지 진행했습니다.
이번 포스팅은 파이썬 코드에서 실제로 DB 백업 파일을 올리고 쉘 스크립트와 마찬가지로 구글 드라이브에서도 과거 파일을 삭제해 줄 것입니다.
1장에서 작성한 쉘 스크립트가 호출될 때, 이번 포스팅에서 작성할 파이썬 스크립트도 동시에 호출되게 할 예정입니다.
그리고 그렇게 완성된 스크립트를 crontab에 등록해 매일 자정마다 실행하도록 스캐쥴링을 해줄 것입니다.
또한, 스크립트가 매번 실행될 때 별도의 파일에서 로그를 관리해 보다 안전하게 백업 진행을 파악할 수 있도록 하는 것이 이번 포스팅의 목표입니다.
즉 정리하자면 이번 포스팅에서 진행할 사항은 다음과 같습니다.
- 파이썬 스크립트를 DB 백업에 적합하도록 개선 작성(오래된 파일 삭제, 신규 백업 파일 업로드 등)
- 쉘 스크립트에서 dump 작업이 완료된 후 파이썬 스크립트를 호출해 구글 클라우드에 업로드
- 백업 과정을 별도의 로그 파일로 관리할 수 있도록 처리
- crontab에서 매일 자정마다 백업이 진행되도록 스캐쥴 등록
위 과정을 모두 마쳤을 때의 백업 자동화 구조의 도식은 아래와 같습니다.
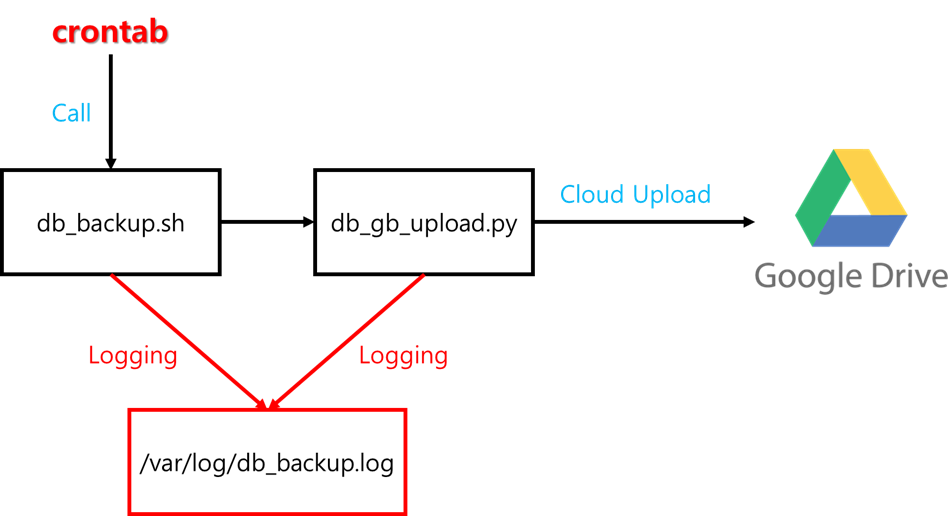
본 포스팅에서 작성하는 스크립트는 그 과정 설명을 위해 자주 내용이 변경될 예정입니다.
과정을 생략하고 최종 결과를 원하실 경우를 위해 포스팅 최 하단에 완성된 스크립트를 첨부해 둘 테니 참고해주시길 바랍니다.
8. db_gb_upload.py (구글 클라우드 업로드 스크립트)
아래는 이전 시간에 작성했던 db_gb_upload.py을 필요에 맞게 수정 작성한 스크립트입니다.
#-*- coding:utf-8 -*-
from __future__ import print_function
import os.path
import sys
from googleapiclient.discovery import build
from google_auth_oauthlib.flow import InstalledAppFlow
from google.auth.transport.requests import Request
from google.oauth2.credentials import Credentials
from googleapiclient.http import MediaFileUpload
import datetime
SCOPES = ['https://www.googleapis.com/auth/drive']
FOLDER_ID = '1cxW1ydMsYW3abtKlHNDmAAOf0Y_ZeQ2v'
# 스크립트의 실제 폴더 경로
SCRIPT_PATH = os.path.dirname(os.path.realpath(__file__))
def main():
creds = None
if os.path.exists(SCRIPT_PATH + '/token.json'):
creds = Credentials.from_authorized_user_file(SCRIPT_PATH + '/token.json', SCOPES)
if not creds or not creds.valid:
if creds and creds.expired and creds.refresh_token:
creds.refresh(Request())
else:
flow = InstalledAppFlow.from_client_secrets_file(
SCRIPT_PATH + '/credentials.json', SCOPES)
creds = flow.run_local_server(port=0)
# Save the credentials for the next run
with open(SCRIPT_PATH + '/token.json', 'w') as token:
token.write(creds.to_json())
service = build('drive', 'v3', credentials=creds)
# 파라미터로 받을 인자
now_str = sys.argv[1]
db_name = sys.argv[2]
file_name = sys.argv[3]
folder_path = sys.argv[4]
backup_rotate = sys.argv[5]
# 2. 오래된 파일 삭제
delete_old_backup(service, now_str, db_name, backup_rotate)
# 1. 파일 업로드
upload(service, file_name, folder_path)
# 업로드
def upload(service, file_name, folder_path):
file_metadata = {
'name': file_name,
'parents': [FOLDER_ID]
}
media = MediaFileUpload(folder_path + file_name, resumable=True)
file = service.files().create(body=file_metadata, media_body=media, fields='id').execute()
print('File ID: %s' % file.get('id'))
def delete_old_backup(service, now_str, db_name, backup_rotate):
file_list = get_backups_in_db_backup(service)
for file in file_list:
# 파일 이름이 삭제 대상인 db_name 이름이 포함 되어있는지 체크
if db_name in file['name']:
"""
TEST_DB-20210624.dump.gz 에서 중간에 날짜 값만 취득
db_name 은 인자 값으로 가지고 오므로 날짜 구분의 시작점을 유추할 수 있다.
"""
file_date_str = file['name'][len(db_name) + 1: (len(db_name) + 9)]
# 날짜 차이를 비교하기 위해 date 객체로 변환
file_date = datetime.datetime.strptime(file_date_str, '%Y%m%d')
now_date = datetime.datetime.strptime(now_str, '%Y%m%d')
# 현재 백업 파일의 날짜 차이
d_diff = now_date - file_date
# backup_rotate 이상의 차이가 난다면 삭제 대상
if d_diff.days > int(backup_rotate):
service.files().delete(fileId=file['id']).execute()
# db_backup 폴더 내 파일 리스트를 전부 호출
def get_backups_in_db_backup(service):
next_page_token = None
backup_list = []
while True:
response = service.files().list(
q=f"parents = '{FOLDER_ID}'",
fields='nextPageToken, files(id, name)',
pageToken=next_page_token).execute()
for file in response.get('files'):
backup_list.append(file)
next_page_token = response.get('nextPageToken', None)
if next_page_token is None:
break
return backup_list
if __name__ == '__main__':
main()
1장에서 작성했던 쉘 스크립트를 연결하기 쉽도록 싹 정리한 스크립트입니다.
해당 스크립트는 코드를 보면 알 수 있지만 아래와 같은 순서로 동작하게 됩니다.
- main()에서 토큰 발급 및 api 객체를 호출합니다.
- delete_old_backup()를 호출해 클라우드 상의 오래된 백업 파일을 삭제합니다.
- upload() 함수로 쉘 스크립트에서 막 생성한 최신 백업본을 클라우드에 업로드합니다.
이 스크립트는 쉘에서 호출되며 그 쉘은 크론 예약 작업으로 호출될 예정입니다.
그런데 크론에 의해 스크립트가 실행될 경우, credits.json과 token.json 파일을 root 경로에서 찾으려 할 겁니다.
따라서 위 두 파일의 실제 경로를 지정해주어야합니다.
경로 관련 코드는 아래와 같이 수정되었습니다.
# 스크립트의 실제 폴더 경로
SCRIPT_PATH = os.path.dirname(os.path.realpath(__file__))
# 이후 credentials.json, token.json은 아래와 같이 위치를 참조합니다
'credentials.json -> SCRIPT_PATH + '/credentials.json'
'token.json -> SCRIPT_PATH + '/token.json'
이제 함수 단위로 코드를 살펴보겠습니다.
def main()
# def main()
# 파라미터로 받을 인자
now_str = sys.argv[1]
db_name = sys.argv[2]
file_name = sys.argv[3]
folder_path = sys.argv[4]
backup_rotate = sys.argv[5]
# 2. 오래된 파일 삭제
delete_old_backup(service, now_str, db_name, backup_rotate)
# 1. 파일 업로드
upload(service, file_name, folder_path)
이번 포스팅에서 스크립트 내 새로 추가된 구문입니다.
sys.argv 배열에서 여러 가지 변수를 할당하고 있습니다.
이 sys.argv는 스크립트가 실행될 때 인자 값으로 받아오는 값을 의미합니다.
아래와 같이 스크립트를 실행하면 인자 값을 얻어올 수 있습니다.
$ db_gd_upload.py [now_str] [db_name] [file_name] [folder_path] [backup_rotate]
리눅스 명령어나 쉘 스크립트에서 인자 값을 받을 때와 유사한 형태로 인자 값을 받아옵니다.
이때, sys.argv[0]은 db_hd_upload.py 즉, 자신의 파일 이름을 인자로 갖습니다.
기본적으로 이러한 인자 값들은 문자열 형태로 받습니다.
그렇게 받아온 인자 값은 "현재시간", "db명", "파일명", "폴더 경로", "삭제할 파일의 날짜 기준"으로 총 5개입니다.
이것은 사람이 직접 입력해줄 것이 아니라 쉘에서 할당하도록 할 것입니다.
def delete_old_backup()
def delete_old_backup(service, now_str, db_name, backup_rotate):
file_list = get_backups_in_db_backup(service)
for file in file_list:
# 파일 이름이 삭제 대상인 db_name 이름이 포함 되어있는지 체크
if db_name in file['name']:
"""
TEST_DB-20210624.dump.gz 에서 중간에 날짜 값만 취득
db_name 은 인자 값으로 가지고 오므로 날짜 구분의 시작점을 유추할 수 있다.
"""
file_date_str = file['name'][len(db_name) + 1: (len(db_name) + 9)]
# 날짜 차이를 비교하기 위해 date 객체로 변환
file_date = datetime.datetime.strptime(file_date_str, '%Y%m%d')
now_date = datetime.datetime.strptime(now_str, '%Y%m%d')
# 현재 백업 파일의 날짜 차이
d_diff = now_date - file_date
# backup_rotate 이상의 차이가 난다면 삭제 대상
if d_diff.days > int(backup_rotate):
service.files().delete(fileId=file['id']).execute()
# db_backup 폴더 내 파일 리스트를 전부 호출
def get_backups_in_db_backup(service):
next_page_token = None
backup_list = []
while True:
response = service.files().list(
q=f"parents = '{FOLDER_ID}'",
fields='nextPageToken, files(id, name)',
pageToken=next_page_token).execute()
for file in response.get('files'):
backup_list.append(file)
next_page_token = response.get('nextPageToken', None)
if next_page_token is None:
break
return backup_list
api 객체가 할당되고 가장 먼저 호출하는 함수입니다.
delete_old_backup()이 호출되자마자 바로 get_backups_in_db_backup()을 호출하고 있습니다.
get_backups_in_db_backup() 함수에서는 구글 드라이브 내 db_backup 폴더에 있는 모든 백업 파일 리스트를 가져오는 기능을 합니다.
response = service.files().list(
q=f"parents = '{FOLDER_ID}'",
fields='nextPageToken, files(id, name)',
pageToken=next_page_token).execute()
여기서 q 파라미터는 query를 의미합니다. parents = folder_id를 정의하면 특정 폴더 안에 있는 파일들을 가져올 수 있습니다.
그리고 nextToken을 통해 만약 페이지가 여러 개일 경우 페이지 끝까지 순환하며 모두 가져오게 됩니다.
pageToken을 지정하지 않을 경우 첫 페이지에 있는 파일들만 호출하도록 되어있습니다.
그리고 가져온 파일의 정보는 fileds 파라미터로 제한해주는 것이 성능상 좋습니다.
여기서는 다음 페이지에 대한 정보와 파일 id, name을 가져옵니다.
파라미터의 정의에 대한 자세한 사항은 아래의 API 문서를 참고해주세요.
https://developers.google.com/drive/api/v3/reference/files/list
Files: list | Google Drive API | Google Developers
nextPageToken string The page token for the next page of files. This will be absent if the end of the files list has been reached. If the token is rejected for any reason, it should be discarded, and pagination should be restarted from the first page of re
developers.google.com
get_backups_in_db_backup()에서 db_backup을 쭉 훑고 나면 아래와 같은 형태로 파일 리스트를 반환합니다.
backup_list = [
{
'id': '파일 아이디',
'file':'파일 이름'
},
{
'id': '파일 아이디',
'file':'파일 이름'
},
...
]
def delete_old_backup(service, now_str, db_name, backup_rotate):
file_list = get_backups_in_db_backup(service)
for file in file_list:
# 파일 이름이 삭제 대상인 db_name 이름이 포함 되어있는지 체크
if db_name in file['name']:
"""
TEST_DB-20210624.dump.gz 에서 중간에 날짜 값만 취득
db_name 은 인자 값으로 가지고 오므로 날짜 구분의 시작점을 유추할 수 있다.
"""
file_date_str = file['name'][len(db_name) + 1: (len(db_name) + 9)]
# 날짜 차이를 비교하기 위해 date 객체로 변환
file_date = datetime.datetime.strptime(file_date_str, '%Y%m%d')
now_date = datetime.datetime.strptime(now_str, '%Y%m%d')
# 현재 백업 파일의 날짜 차이
d_diff = now_date - file_date
# backup_rotate 이상의 차이가 난다면 삭제 대상
if d_diff.days > int(backup_rotate):
service.files().delete(fileId=file['id']).execute()
delete_old_backup() 함수의 핵심은 클라우드에 업로드되어있는 파일명에서 날짜 값을 추출해 현재 날짜와 비교 후 오래된 백업 파일을 클라우드에서 지우는 것입니다.
날짜 정보를 가져오기 쉽게 하기 위해 사전에 스크립트에서 인자 값으로 db_name을 받아왔습니다.
db_name이 백업 파일의 제일 앞부분에 위치하기 때문에 날짜 정보를 인덱스로 계산해 가져올 수 있습니다.
파이썬은 날짜 객체끼리의 더하기 빼기로 날짜를 비교할 수 있습니다.
현재 날짜와 백업 파일들의 날짜의 차이가 backup_rotate 보다 클 경우, 클라우드에서 파일을 삭제하게 됩니다.
한 가지 주의할 점은, api를 이용해 파일을 지울 경우 복구가 불가능합니다.
휴지통을 거치지 않고 바로 삭제하기 때문에 중요한 파일을 다룰 경우에는 신중에 신중을 기해주세요.
9. Python 스크립트 테스트
먼저 스크립트가 있는 곳에 백업 파일을 두고 파이썬 스크립트만 인자 값을 주어 실행해보겠습니다.
본 포스팅에서는 BACKUP_TEST-20210624.dump 파일을 예시로 하겠습니다.
backup_rotate가 제대로 동작하는지 확인하기 위해 미리 구글 드라이브에 이전 날짜의 파일을 10개 정도 만들고 backup_rotate를 3 정도로 설정해보겠습니다.

스크립트가 있는 경로에서 아래와 같이 스크립트를 실행합니다.
$ python3 db_gd_upload.py 20210624 BACKUP_TEST BACKUP_TEST-20210624.dump.gz ./ 3
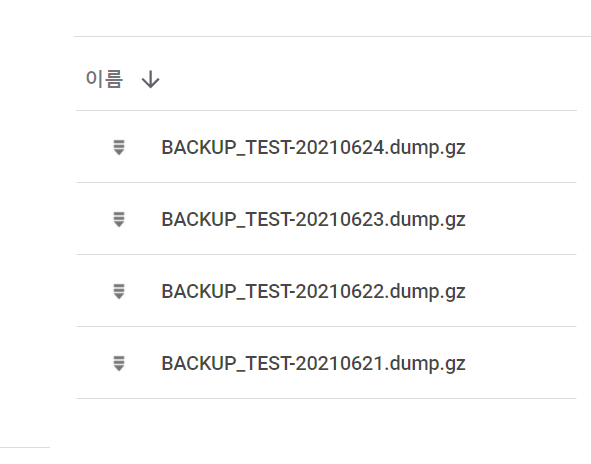
실행 결과 의도대로 정확히 동작하는 것을 확인할 수 있었습니다.
10. 스크립트 로깅 처리
DB 백업 자동화는 매우 면밀히 모니터링해야 하는 작업 중 하나입니다.
따라서 스크립트를 실행할 때, 그 과정에 대한 기록을 남기는 것이 중요한데요, 로깅 처리 시에 주의할 점은 로그 파일이 디스크 용량을 심하게 차지하지 않도록 해야 한다는 점입니다.
주의 깊게 처리하지 않을 경우 디스크 용량을 100% 차지하게 될 시점이 올 수도 있으며 이때는 시스템이 부팅조차 하지 않는 최악의 상황이 올 수도 있습니다.
따라서 로그 파일은 적절한 주기를 갖도록 하는 것이 중요합니다.
- 1주일에 한 번 로그 파일을 압축한다.
- 과거 1달 이후의 로그 압축 파일은 삭제한다.
- 일정 용량 이상 도달하면 압축한다.
등과 같은 주기를 정의해 주어야 안전하게 로그 파일을 관리할 수 있습니다.
대부분의 리눅스는 이러한 로그파일의 주기를 관리해주는 패키지가 자동으로 설치되는데 logrotate가 그것입니다.
먼저 logrotate를 설정하기에 앞서 /var/log 디렉터리에 db_backup.log 파일을 생성해 줍니다.
sudo 권한으로 생성해야 합니다.
$ sudo touch /var/log/db_backup.log
$ sudo chmod 755 /var/log/db_backup.log

이제 logrotate.conf 파일을 열어 기본 로그 파일 관리 구조를 살펴보겠습니다.
$ sudo vim /etc/logrotate.conf

차례대로 보자면
- weekly: 매주마다 순환하며 로그 파일들을 처리한다
- rotate 4: 순환될 때 보관하는 로그 파일의 수
- create: 비어있는 새 로그파일을 생성
- dateext: 날짜 형식의 확장자를 사용한다
- compress: 순환 대상이 된 파일을 압축한다.
- include /etc/logrotate.d: 그밖에 개별적으로 설정한 정보들은 /etc/logrotate.d에 있는 파일들에서 포함한다
/etc/logrotate.d 경로는 아래와 같이 파일이 위치해 있습니다.

자세한 사항은 아래의 링크를 참고해 주세요.
https://zetawiki.com/wiki/Logrotate_%EB%94%94%EB%A0%89%ED%8B%B0%EB%B8%8C
Logrotate 디렉티브 - 제타위키
다음 문자열 포함...
zetawiki.com
db_backup.log에 대한 주기를 간단히 설정해줍니다.
$ sudo vim /etc/logrotate.d/db_backup
## 아래의 내용 입력 ##
/var/log/db_backup.log
{
rotate 4
weekly
missingok
compress
}
한번 작성해 두면 예약 작업으로 인해 저절로 새로 작성된 프로필이 적용이 되지만 본 포스팅에서는 수동으로 적용하겠습니다.
$ sudo logrotate /etc/logrotate.d/db_backup
이제 쉘 스크립트와 파이썬에도 이 db_backup.log에 작업 과정이 기록되도록 코드를 추가하겠습니다.
db_backup.sh
#/bin/sh
DBUSER=데이터베이스 유저명을 입력합니다.
DBPASS=데이터베이스 패스워드를 입력합니다.
DBNAME=백업할 데이터베이스이름을 입력합니다(따옴표 생략)
BACKUP_DIR=/home/db_backup# 백업할 경로
BACKUP_ROTATE=30 # 현재 시점 30일 전보다 과거의 파일을 삭제하기 위한 변수
today=$(date +%Y%m%d)
# [new] 로그 파일 경로
LOG_FILE=/var/log/db_backup.log
# [new] 로그 함수
logging() {
level=$1
message=$2
echo "[$(date +%Y-%m-%d_%T)] [db_backup.sh] [${level}] : ${message}" >> ${LOG_FILE}
}
# dump 실행
/usr/bin/mysqldump -u${DBUSER} -p${DBPASS} ${DBNAME} > ${BACKUP_DIR}/${DBNAME}-${today}.dump
# dump 파일 생성 성공 여부 체크
if [ $? -eq 0 ]; then
# [new] 로그 기록
logging 'INFO' 'mysqldump command done!'
# dump 파일 압축
gzip ${BACKUP_DIR}/${DBNAME}-${today}.dump
# [new] 로그 기록
logging 'INFO' "Created ${BACKUP_DIR}/${DBNAME}-${today}.dump"
# 외부에서 함부로 지울 수 없도록 파일의 소유권을 root로 지정
chown root:root ${BACKUP_DIR}/${DBNAME}-${today}.dump.gz
# root 이외의 계정은 열람만 가능하고 수정은 불가 하도록 권한 설정
chmod 755 ${BACKUP_DIR}/${DBNAME}-${today}.dump.gz
# 오래된 백업 파일 삭제
find ${BACKUP_DIR} -name ${DBNAME}-*.dump.gz -mtime +${BACKUP_ROTATE} | xargs rm -f
# [new] 로그 기록
b_count=$(find ${BACKUP_DIR} -name ${DBNAME}-*.dump.gz | wc -l)
logging 'INFO' "Backup Count: ${b_count}"
else
# [new] 로그 기록
logging 'ERROR' 'mysqldump command failed!'
fi
파이썬 코드에도 마찬가지로 로그 기능을 추가합니다.
db_gd_upload.py
#-*- coding:utf-8 -*-
import ...
# [new] 패키지 추가
import logging
import traceback
...
# [new] 로그 파일 위치 추가
LOG_FILE = '/var/log/db_backup.log'
# [new] 설정 정보
logging.basicConfig(filename=LOG_FILE,
level=logging.DEBUG,
format='[%(asctime)s] [db_gb_backup.py] [%(levelname)s]: %(message)s',
datefmt='%Y-%m-%d_%I:%M:%S')
# [new] 예외가 발생했을 때를 위한 후킹 처리
def exception_hook(exc_type, value, tb):
err_str = str(exc_type) + ' ' + str(value) + ' ' + str(traceback.format_tb(tb)[0])
logging.error(err_str)
sys._excepthook(exc_type, value, traceback)
sys.exit(1)
# [new] 예외가 발생했을 때를 위한 후킹 처리
sys.excepthook = exception_hook
def main():
. . .
service = build('drive', 'v3', credentials=creds)
# [new] 로그 추가
logging.info("init service")
. . .
# 1. 오래된 파일 삭제
delete_old_backup(service, now_str, db_name, backup_rotate)
# [new] 로그 추가
logging.info("deleted old backup from Google Drive")
# 2. 파일 업로드
upload(service, file_name, folder_path)
# [new] 로그 추가
logging.info("uploaded backup file from Google Drive")
. . .
기존 파일에서 new 주석이 달린 부분만 적절한 위치에 추가해주면 됩니다.
이제 쉘에서 파이썬 코드를 호출시켜야 하는데, 그전에 로그가 제대로 표시되는지 테스트해보겠습니다.


두 스크립트 다 정상적으로 로그를 출력하는 것을 확인했습니다.
11. 쉘 스크립트에서 파이썬 코드 호출
#/bin/sh
. . .
# 파이썬 스크립트 참조 경로를 스크립트가 있는 현재 폴더에서 찾도록 변경
RELATIVE_DIR=`dirname "$0"`
BACKUP_DIR=${RELATIVE_DIR}/.. # 백업할 경로
...
# dump 파일 생성 성공 여부 체크
if [ $? -eq 0 ]; then
. . .
logging 'INFO' "Backup Count: ${b_count}"
# 파이썬 스크립트 호출 추가
/usr/bin/python3 ${RELATIVE_DIR}/db_gd_upload.py ${today} ${DBNAME} ${DBNAME}-${today}.dump.gz ${BACKUP_DIR}/ ${BACKUP_ROTATE}
else
. . .
fi
호출 방법은 간단합니다. 쉘에서는 python3 ~ 이런 식으로 호출하기보다는 가급적 패키지가 설치되어있는 절대 경로를 모두 입력하는 것이 좋습니다.
리눅스에서는 보통 파이썬이 /usr/bin/python3에 설치되어있는데 설치되어있는 장소가 다르다면 그에 맞게 작성해줍니다.
파이썬 스크립트를 cron에 의해 호출하게 될 경우 역시, 쉘 파일이 있는 실제 경로를 참조해야 하기 때문에 RELATIV_DIR 변수를 추가해 주었습니다.
이제 쉘 스크립트를 호출하는 것만으로 파이썬 스크립트까지 모두 한 번에 실행이 가능해졌습니다.
아래 명령어로 스크립트를 실행합니다.
$ sudo /home/db_backup/db_backup.sh

이와 같은 반환 문이 출력되었다면 정상 적용된 것입니다.
11. crontab 예약 작업 등록
crontab 예약 작업을 등록하기 전에 db_backup 폴더를 확인해보겠습니다.
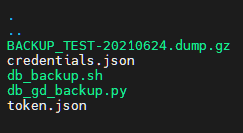
실행 스크립트와 백업 파일이 혼재해있어 조금 지저분해 보입니다.
실행 스크립트를 db_backup 안에 backup_scripts라는 이름의 하위 폴더를 만들어 그곳으로 이동시키겠습니다.
스크립트에서 참조하는 경로는 앞선 작업에서 실제 경로를 참조하도록 했기 때문에 그냥 이동시켜도 괜찮습니다.
$ cd /home/db_backup
$ sudo mkdir backup_scripts
$ sudo mv db_backup.sh db_gd_backup.py credentials.json token.json backup_scripts/

보다 깔끔하게 정리되었습니다.
이제 본 포스팅의 마지막 단계인 crontab 예약 작업을 등록하겠습니다.
아래의 명령어로 crontab을 열고 스캐쥴을 등록합니다.
$ sudo crontab -e

작성이 완료됐다면 편집기를 닫고 아래의 명령어로 crontab을 적용합니다.
$ sudo service cron restart
이것으로 아래의 모든 과정이 완료되었습니다.
- DB 백업 쉘 스크립트 작성, 오래된 백업 파일 삭제
- Google Drive API 사용 설정
- Python을 이용한 API 호출, 클라우드 백업, 클라우드 내 오래된 백업 파일 삭제
- 스크립트 로깅 처리
- crontab을 이용한 스캐쥴링 작업
아래는 위 과정을 거쳐 완성된 쉘과 파이썬 스크립트 파일입니다.
포스팅에서는 다루지 않았지만 Python의 os.system 함수를 이용해 sh의 기능을 파이썬에서 실행하는 것도 가능합니다.
아래는 하나로 합친 파일입니다.
코드를 보시면 아마 동작 의도를 파악할 수 있을 겁니다.
긴 글 읽으시느라 고생 많으셨습니다.
저도 이번 포스팅을 준비하면서 서버 모니터링은 꼼꼼함이 중요하구나라는 것을 많이 느꼈습니다.
사실 본 포스팅의 내용도 부족한 면이 많으므로 방문해주시는 분들은 보다 견고한 백업 자동화를 구축해 보시기를 희망합니다.
이것으로 포스팅을 마치겠습니다.
'Dev > linux' 카테고리의 다른 글
| [Linux] Shell & crontab, Google Drive api를 이용한 Mysql 데이터베이스 백업 (2) (0) | 2021.06.25 |
|---|---|
| [Linux] Shell & crontab, Google Drive api를 이용한 Mysql 데이터베이스 백업 (1) (0) | 2021.06.25 |
| [Linux] Raspberry Pi 4B 와 카메라 모듈을 이용한 실시간 스트리밍 구축 (6) | 2021.05.30 |
| [Linux] vim 코드 자동완성 사용하기 (0) | 2020.12.08 |
| [Linux] 파일 접근 허가 상수 (0) | 2020.11.30 |



