본 포스팅에서는 선택, 삽입 버블 정렬에 대한 포스팅입니다.
구현 언어는 Python입니다.
이 세 가지 정렬 방식은 다른 알고리즘에 비해 성능이 떨어지지만 구현이 쉽고 코드 읽기가 쉽다는 장점이 있습니다.
(선택과 버블 정렬은 데이터의 상태와 관계없이 O(n²)의 시간 복잡도를 가지고 삽입 정렬은 데이터의 상태에 따라 O(n)의 이상적인 시간 복잡도를 가지지만 최악의 경우 O(n²)의 시간 복잡도를 갖는다고 합니다.
우선 본 포스팅을 위해 위 3가지 정렬 기능을 하나의 스크립트로 미리 작성해두었습니다.
import copy
class Sorts:
def __init__(self, array):
self.array = array
#결과 출력용 함수
def print_result(self, name, array):
print(f'[{name}]')
print('Origin:\t{}'.format(self.array))
print('Mod:\t{}'.format(array))
# 삽입 정렬
def insertion(self):
array = copy.deepcopy(self.array)
for i in range(len(array)):
key = array[i]
j = i - 1
while j >= 0 and array[j] > key:
array[j + 1] = array[j]
j = j - 1
array[j + 1] = key
self.print_result('Insertion Sort', array)
# 선택 정렬
def selection(self):
array = copy.deepcopy(self.array)
for i in range(len(array) - 1):
key_idx = i
for j in range(i + 1, len(array)):
if array[j] < array[key_idx]:
key_idx = j
tmp = array[key_idx]
array[key_idx] = array[i]
array[i] = tmp
self.print_result('Selection Sort', array)
# 버블 정렬
def bubble(self):
array = copy.deepcopy(self.array)
for i in range(len(array) - 1):
for j in range(len(array) - 1):
if array[j] > array[j + 1]:
tmp = array[j]
array[j] = array[j + 1]
array[j + 1] = tmp
self.print_result('Bubble Sort', array)
if __name__=='__main__':
#정렬되지 않은 Raw 데이터
array = [9, 8, 4, 1, 3, 2, 5, 7, 6]
sorts = Sorts(array)
sorts.insertion()
sorts.selection()
sorts.bubble()
코드 구성은 순전히 제가 임의로 작성한 스타일입니다.
코드 중 copy.deepcopy 함수와 print_result함수는 배열을 깊은 복사 해서 정렬 전과 후를 비교하기 위한 것이니 따로 본인이 작성할 경우 안 쓰셔도 됩니다.
1. 삽입정렬
# 삽입 정렬
def insertion(self):
array = copy.deepcopy(self.array)
for i in range(len(array)):
key = array[i]
j = i - 1
while j >= 0 and array[j] > key:
array[j + 1] = array[j]
j = j - 1
array[j + 1] = key
삽입 정렬은 전체 배열을 순회하며 대상 값이 이전 인덱스의 값보다 작은 지를 체크합니다.
만약 이전 인덱스보다 작다면 값들을 뒤쪽으로 밀고 그 앞쪽에 대상 값을 배치하는 특징이 있습니다.
예시를 들자면
[1, 3, 4, 2]라는 값에서 현재 대상 값이 2일 경우 배열 내 3, 4 값을 한 자리씩 뒤로 밀고 1 뒷자리로 대상 값을 집어넣는 개념입니다.
따라서 한 자리씩 값들을 뒤로 밀다보면 원본 변수가 사라지기 때문에 대상 값을 key라는 변수에 보존한 상태에서 연산이 시작됩니다.
for i에서 전체 값들을 순회하는데, 자기 자신보다 이전의 값들을 검색하는 특성상 알고리즘은 i 보다 큰 값을 대상으로 잡습니다.
이해하기 쉽게 동작 절차를 나타내는 이미지를 준비했습니다.
아래의 이미지를 참고해주세요.
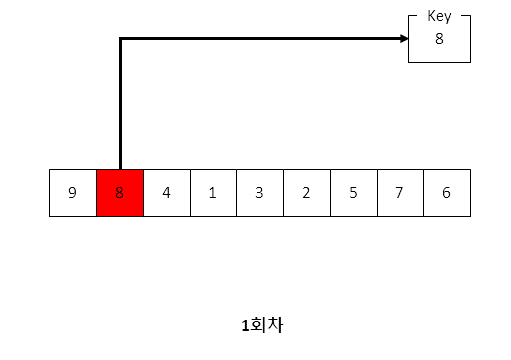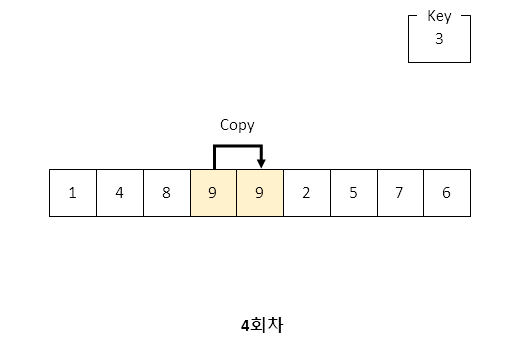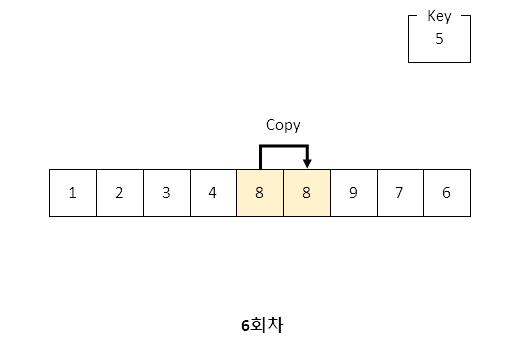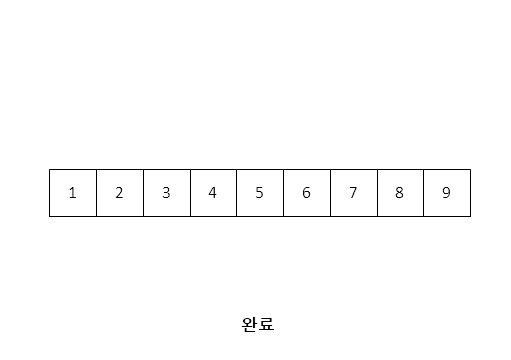
이미지를 보면 사실 값들을 뒤로 민다라기보다는 뒤로 복사하는 과정을 거치는 것을 알 수 있습니다.
결과는 밀어 내고 그 사이에 집어넣은 것이 되는 것이지요.
2. 선택 정렬
# 선택 정렬
def selection(self):
array = copy.deepcopy(self.array)
for i in range(len(array) - 1):
key_idx = i
for j in range(i + 1, len(array)):
if array[j] < array[key_idx]:
key_idx = j
tmp = array[key_idx]
array[key_idx] = array[i]
array[i] = tmp
선택 정렬은 배열을 순회하며 첫 key 값을 잡고 배열 내에 존재하는 가장 작은 값과 정렬 대상의 위치를 서로 바꿔 정렬하는 알고리즘입니다.
선택 정렬은 본 포스팅에서 소개하는 알고리즘 중 특이하게 배열의 인댁스 값을 제어하는 식으로 논리를 풀어나갑니다.
개인적으로 이 알고리즘은 "좌표(인덱스)"를 선택하는 알고리즘이다 라는 식으로 기억하면 떠올리기 쉽지 않을까 합니다.
또한 선택 정렬의 특징으로는 바깥쪽 for 문 즉, 배열의 값들 중 비교의 주가 되는 숫자로 마지막 인덱스 값을 지목하지 않습니다.
이유는 선택 정렬에서의 비교 주체와 비교 대상은 [현재 위치]와 [현재 위치 + n] 이기 때문이죠.
마지막 값을 지목하는 역할은 for j에게 맡기면 됩니다.
그래서 for j는 i + 1부터 시작합니다.
예시를 들자면 [1, 3, 4, 2]라는 배열을 정렬하고자 할 때, 1회 차 때
비교 주체: 1
비교 대상: 3
이 되는 것입니다.
아래의 이미지를 통해 알고리즘의 진행 절차를 쉽게 파악할 수 있습니다.

i 값을 파란색, key 값을 붉은색, 비교 대상이 되는 숫자를 노란색으로 구분했습니다.
이미지와 같이 key 값은 j 값에 의해 순환되는 도중 자기 자신보다 작은 숫자를 새로운 key로 지목하고 있습니다.
for j가 한차례 완료되면 자연스레 key 값은 자기 자신과 배열 내 가장 작은 숫자로 추려지게 되는 것이지요.
여담이지만 Python에서는 두 변수 간의 스왑 기능을 제공하고 있습니다.
그런데 구태여 tmp를 통해 변수를 스왑 한 이유는 알고리즘의 진행 과정을 보다 명확하게 하기 위함이므로 본인의 입맛에 맞게 적절히 수정해주시면 되겠습니다.
3. 버블 정렬
# 버블 정렬
def bubble(self):
array = copy.deepcopy(self.array)
for i in range(len(array) - 1):
for j in range(len(array) - 1):
if array[j] > array[j + 1]:
tmp = array[j]
array[j] = array[j + 1]
array[j + 1] = tmp
버블 정렬은 본 포스팅에서 소개하는 알고리즘 중 가장 효율로는 떨어지는 정렬 알고리즘입니다.
그 이유는 for 문을 2중으로 사용하는데, 연산 과정에서 이미 정렬이 된 부분도 정렬 여부를 2중, 3중, ... 으로 계속 검사하기 때문입니다.
즉 데이터의 규모와 관계없이 연산 수행 횟수는 무조건 N² 가 됩니다.
버블 정렬의 특징으로는 현재 값과 이웃한 다음 값을 비교한다는 점입니다.
비교 주체가 이웃한 비교 대상보다 크다면 서로의 위치를 바꿉니다.
[9, 8, 4, 1, 3, 2, 5, 7, 6]을 예시로 할 때, 9, 8을 비교해 서로의 자리를 바꿔
[8, 9, 4, 1, 3, 2, 5, 7, 6], 배열에서 다음 비교 주체인 9와, 4를 비교해 서로의 자리를 바꿔
[8, 4, 9, 1, 3, 2, 5, 7, 6] 이런 식으로 정렬을 수행합니다.
아래의 이미지를 통해 동작 과정을 확인해 주세요.

위 이미지에서는 4회 차에서 완료가 되는 것처럼 보이지만 내부에서는 for문을 N² 횟수를 모두 수행합니다.
10개의 데이터는 10² = 100번, 1000개의 데이터는 100² = 10000번 모두 끝까지 다 수행합니다.
다만 for문이 수행될수록 Swap 되는 데이터 빈도가 적어질 뿐이지요.
이것으로 삽입, 선택, 버블 정렬에 대한 포스팅을 마치겠습니다.
한 가지 부탁드리고 싶은 사항은, 예시에서 사용된 gif 이미지 만드는데 정말 고생 많이 했습니다...
다른 매체에 무단으로 제 포스팅을 퍼가는 경우가 간혹 가다 있는데, 퍼가시는 건 좋습니다만 출처는 꼭 남겨주시길 간곡히 부탁드립니다.
열람해 주셔서 감사합니다
'Dev > Algorithm' 카테고리의 다른 글
| [Algorithm] 에라토스테네스의 체 (0) | 2021.04.24 |
|---|---|
| [Algorithm] Binary Search(이진 탐색) (0) | 2020.09.17 |
| [Algorithm] 정렬 - 가장 큰 수 (0) | 2020.08.20 |
| [Algorithm] 정렬 - K번째 수 (0) | 2020.08.17 |


